Was this page helpful?
Repair¶
Repair is important to make sure that data across the nodes is consistent. To learn more about repairs please consult this ScyllaDB University lesson.
Note
If you are using ScyllaDB Manager deployed by ScyllaDB Operator, see dedicated ScyllaDB Operator documentation.
ScyllaDB Manager automates the repair process and allows you to configure how and when repair occurs.
ScyllaDB Manager repair task revolves around scheduling many ScyllaDB repair jobs with selected --intensity in --parallel.
Repair task is responsible for fully repairing all tables selected with --keyspace parameter, while a single repair job repairs
chosen (by ScyllaDB Manager) token ranges of a given table owned by a specific replica set. All nodes from this replica set take part in
the repair job and any node can take part only in a single repair job at any given time.
Note that ScyllaDB Manager stops tablets migration for the duration of repair.
When you create a cluster a repair task is automatically scheduled. This task is set to occur each week by default, but you can change it to another time, change its parameters or add additional repair tasks if needed.
Tablet repair¶
Regular repair task handles both Vnode and Tablet replicated keyspaces. It also supports –keyspace-replication flag allowing to filter keyspaces by their replication type.
Apart from the regular repair task, there is a dedicated tablet repair task optimized for tablet keyspaces. This lightweight task is resilient to topology changes and uses ScyllaDB’s incremental repair feature, allowing it to run more frequently with minimal overhead.
Regular and tablet repair tasks can run in parallel only when regular repair task uses –keyspace-replication=vnodes. Otherwise, the second task will fail to start and will be rescheduled according to its retry mechanism.
Features¶
Glob patterns to select keyspaces or tables to repair
Parallel repairs
Control over repair intensity and parallelism even for ongoing repairs
Ranges batching
Repair order improving performance and stability
Resilience to schema changes
Retries
Pause and resume
Parallel repairs¶
Each node can take part in at most one ScyllaDB repair job at any given moment, but ScyllaDB Manager can repair distinct replica sets in a token ring in parallel. This is beneficial for big clusters. The following diagram presents a benchmark results comparing different parallel flag values. In a benchmark we ran 9 ScyllaDB 2020.1 nodes on AWS i3.2xlarge machines under 50% load, for details check this blog post
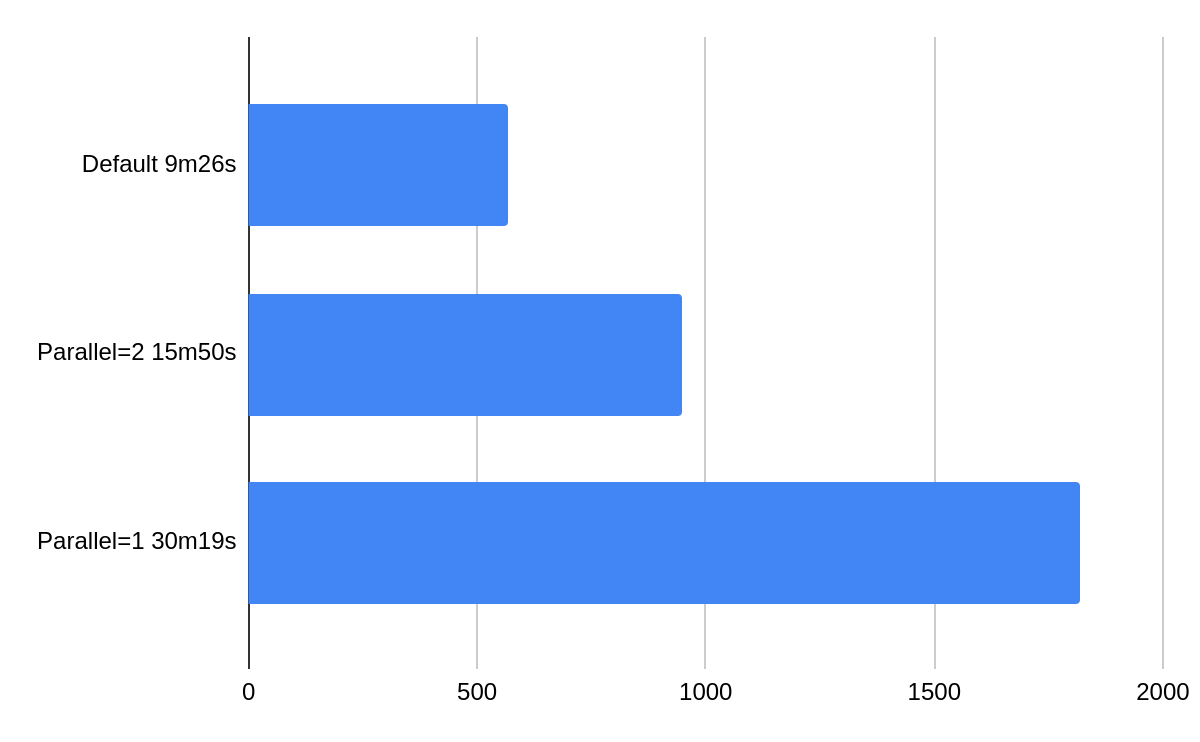
By default ScyllaDB Manager runs repairs with full parallelism, you can change that using sctool repair –parallel flag.
Maximal effective parallelism¶
- Max parallelism is determined by:
the constraint that each node can only take part in one ScyllaDB repair job at any given moment.
ScyllaDB repair job targeting the full replica set of the repaired token range.
For example, let’s assume a cluster with 2 datacenters, 5 nodes each.
When you repair the keyspace my_keyspace with replication = {'class': 'NetworkTopologyStrategy', 'dc1': 2, 'dc2': 3},
max parallelism is equal to 1, because each ScyllaDB repair job targets a full replica set of the repaired token range.
Every replica set consists of 2 nodes from dc1 and 3 nodes from dc2,
so it’s impossible to schedule 2 repair jobs to run simultaneously (dc2 lacks one more node for it to be possible).
Repair is performed table by table and keyspace by keyspace, so max effective parallelism might change depending on which keyspace is being repaired.
Repair intensity¶
Intensity specifies how many token ranges can be repaired in a ScyllaDB node at every given time. The default intensity is one, you can change that using sctool repair –intensity flag.
In that case, the number of token ranges is calculated based on node memory and adjusted to ScyllaDB’s maximum number of ranges that can be repaired in parallel. If you want to repair faster, try using intensity zero.
Note that the less the cluster is loaded the more it makes sense to increase intensity. If you increase intensity on a loaded cluster it may not give speed benefits since cluster have no resources to process more repairs. In our experiments in a 50% loaded cluster increasing intensity from 1 to 2 gives about 10-20% boost and increasing it further will have little impact.
Maximal effective intensity¶
Max intensity is calculated based on the max_repair_ranges_in_parallel value (present in ScyllaDB logs).
This value might be different for each node in the cluster.
As each ScyllaDB repair job targets some subset of all nodes and
ScyllaDB Manager avoids repairing more than max_repair_ranges_in_parallel on any node,
the max effective intensity for a given repair job is equal to the minimum max_repair_ranges_in_parallel
value of nodes taking part in the job.
Ranges batching¶
In order to improve cluster utilization, ScyllaDB Manager sends all ranges owned by given replica set in a single repair job.
The --intensity constraint is ensured by the ranges_parallelism repair job parameter.
Even though this improves repair performance (especially for tablet keyspaces), it reduces task granularity.
In order to ensure task progress, batching is disabled (ScyllaDB Manager sends --intensity amount of ranges per repair job),
when task execution is resumed after finishing with error or when it ran out of the maintenance window (--window flag).
Changing repair speed¶
Repair speed is controlled by two parameters: --parallel and --intensity
Those parameters can be set when you:
Schedule a repair with sctool repair
Update a repair specification with sctool repair update
Update a running repair task with sctool repair control
More on the topic of repair speed can be found in Repair faster and Repair slower articles.
Repair order¶
ScyllaDB Manager repairs keyspace by keyspace and table by table in order to achieve greater repair stability and performance.
Keyspaces and tables are ordered according to the following rules:
repair internal (with
systemprefix) tables before user tablesrepair base tables before Materialized Views and Secondary Indexes
repair smaller keyspaces and tables first
Note
Ensuring that base tables are repaired before views is possible only when ScyllaDB Manager has CQL credentials to repaired cluster.